データの特徴を抽出する
その特徴に基づいて未知の現象に対する予測を行う
「特徴」って何?
y=w1x1+w2x2+⋯+wMxMy=w_1x_1+w_2x_2+\dots+w_Mx_M y=w1x1+w2x2+⋯+wMxM
y=wTxy=\bm{w}^T\bm{x} y=wTx
しかし既知のデータもすべて綺麗にこの式に従うわけではない
各サンプル(既知のデータのこと)のnnn番目について次のような式を考えられる
yn=wTxn+ϵny_n = \bm{w}^T\bm{x}_n + \epsilon_n yn=wTxn+ϵn
ϵ\epsilonϵがnnn番目のサンプルの誤差あるいはノイズを表している
切片は?2 次以上は考えられないの?
Sig(a)=11+e−a\mathrm{Sig}(a) = \frac{1}{1+e^{-a}} Sig(a)=1+e−a1
μn=wTxn\mu_n = \bm{w}^T\bm{x_n} μn=wTxn
fk(a)=SMk(a)=eak∑i=1Keaif_k(\bm{a}) = \mathrm{SM}_k(\bm{a}) = \frac{e^{a_k}}{\sum^K_{i=1} e^{a_i}} fk(a)=SMk(a)=∑i=1Keaieak
つまり…
元のデータY∈RD×N\bm{Y} \in \mathbb{R}^{D\times N}Y∈RD×N を重みW∈RM×D\bm{W}\in \mathbb{R}^{M\times D}W∈RM×Dと削減したデータX∈RM×N(M<D)\bm{X} \in \mathbb{R}^{M\times N} (M < D)X∈RM×N(M<D)を用いて近似したい
Y≈WTX\bm{Y} \approx \bm{W}^T\bm{X} Y≈WTX
どうやってW\bm{W}Wを求めるの?
などなど
定義 関数p:x∈RM→Rp: \bm{x} \in \mathbb{R}^M \rightarrow \mathbb{R}p:x∈RM→Rで、p(x)≥0p(\bm{x}) \geq 0p(x)≥0かつ
p(x)dx=∫⋯∫p(x1,⋯xM)dx1⋯dxM=1p(x) dx = \int \cdots \int p(x_1, \cdots x_M) dx_1\cdots dx_M = 1 p(x)dx=∫⋯∫p(x1,⋯xM)dx1⋯dxM=1
となるもの
1 変数は去年?やった
P(X≤x)=∫−∞xp(t)dtP(X \leq x) = \int_{-\infty}^x p(t) dt P(X≤x)=∫−∞xp(t)dt
多変数でも雰囲気は同じ
勘違い
結局、離散型確率分布の確率質量関数は、連続型確率分布の確率密度関数の積分(連続的な和)をシグマ(離散的な和)に変えただけです。
よって、今後の議論では積分を用いて連続型確率分布について考えますが、同様の議論が離散型確率分布にも適当可能です。
P(x≤X,y≤Y)=∫−∞x∫−∞yp(s,t)dtdsP(x \leq X, y \leq Y) = \int_{-\infty}^{x} \int_{-\infty}^{y} p(s, t) dt ds P(x≤X,y≤Y)=∫−∞x∫−∞yp(s,t)dtds
p(y)=∫−∞∞p(x,y)dxp(y) = \int_{-\infty}^{\infty} p(x,y) dx p(y)=∫−∞∞p(x,y)dx
p(x∣y)=p(x,y)p(y)p(x|y) = \frac{p(x,y)}{p(y)} p(x∣y)=p(y)p(x,y)
p(x∣y)=p(y∣x)p(x)p(y)p(x|y) = \frac{p(y|x)p(x)}{p(y)} p(x∣y)=p(y)p(y∣x)p(x)
p(x,y)=p(x)p(y)p(x,y) = p(x)p(y) p(x,y)=p(x)p(y)
p(x∣y)=p(x)p(x|y) = p(x) p(x∣y)=p(x)
状況: 2 つの袋 a, b があり、それぞれに赤と白の玉が入っている
a には赤 2 コ, 白 1 コ
b には赤 1 コ, 白 3 コ 操作:
まず 1/2 の確率で a, b の袋を選ぶ
その後にその袋から玉を取り出す
p(x=a)=12,p(x=b)=12p(x=a) = \frac{1}{2}, p(x=b) = \frac{1}{2} p(x=a)=21,p(x=b)=21
p(x,y)=p(y∣x)p(x)p(x, y) = p(y|x)p(x)p(x,y)=p(y∣x)p(x)が使える 袋 a を選択し、かつ、赤玉を取り出す確率は、
p(x=a,y=r)=p(y=r∣x=a)p(x=a)=14×12=18\begin{aligned}p(x=a, y=r) &= p(y=r | x=a)p(x=a) \\ &= \frac{1}{4} \times \frac{1}{2} = \frac{1}{8}\end{aligned} p(x=a,y=r)=p(y=r∣x=a)p(x=a)=41×21=81
p(y=r)=∑xp(y=r,x)=1/3+1/8=11/24p(y=r) = \sum_x p(y=r, x) = 1/3+1/8=11/24 p(y=r)=x∑p(y=r,x)=1/3+1/8=11/24
メインテーマ!
p(x=a∣y=r)=p(y=r∣x=a)p(x=a)p(y=r)=8/11p(x=a|y=r) = \frac{p(y=r|x=a)p(x=a)}{p(y=r)} = 8/11 p(x=a∣y=r)=p(y=r)p(y=r∣x=a)p(x=a)=8/11
p(y1=r,y2=r,y3=w∣x)=p(y1=r∣x)p(y2=r∣x)p(y3=w∣x)p(y_1=r, y_2=r, y_3=w|x) = p(y_1=r|x)p(y_2=r|x)p(y_3=w|x) p(y1=r,y2=r,y3=w∣x)=p(y1=r∣x)p(y2=r∣x)p(y3=w∣x)
Bayes の定理より
p(x∣y1=r,y2=r,y3=w)=p(y1=r,y2=r,y3=w∣x)p(x)p(y1=r,y2=r,y3=w)=p(y1=r∣x)p(y2=r∣x)p(y3=w∣x)p(x)p(y1=r,y2=r,y3=w)\begin{aligned}p(x|y_1=r, y_2=r, y_3=w) &= \frac{p(y_1=r, y_2=r, y_3=w|x)p(x)}{p(y_1=r, y_2=r, y_3=w)} \\ &= \frac{p(y_1=r|x)p(y_2=r|x)p(y_3=w|x)p(x)}{p(y_1=r, y_2=r, y_3=w)}\end{aligned} p(x∣y1=r,y2=r,y3=w)=p(y1=r,y2=r,y3=w)p(y1=r,y2=r,y3=w∣x)p(x)=p(y1=r,y2=r,y3=w)p(y1=r∣x)p(y2=r∣x)p(y3=w∣x)p(x)
ここで分母の計算が面倒 (周辺化を行う必要がある)
p(x∣y1=r,y2=r,y3=w)p(x|y_1=r, y_2=r, y_3=w)p(x∣y1=r,y2=r,y3=w)はxxxのすべての場合について足し合わせると 1 になるので、分子のみを計算して後で合計が 1 になるように調整する ← 今後、頻出するテクです
p(x=a∣y1=r,y2=r,y3=w)∝p(y1=r∣x=a)p(y2=r∣x=a)p(y3=w∣x=a)p(x=a)p(x=a|y_1=r, y_2=r, y_3=w) \propto p(y_1=r|x=a)p(y_2=r|x=a)p(y_3=w|x=a)p(x=a) p(x=a∣y1=r,y2=r,y3=w)∝p(y1=r∣x=a)p(y2=r∣x=a)p(y3=w∣x=a)p(x=a)
p(x=a∣y1=r,y2=r,y3=w)=2/272/27+3/128=256337p(x=a|y_1=r, y_2=r, y_3=w) =\frac{2/27}{2/27+3/128}=\frac{256}{337} p(x=a∣y1=r,y2=r,y3=w)=2/27+3/1282/27=337256
このように複数の独立なデータがあれば、より確からしい推論を逐次的に行える。
p(x∣y1)∝p(y1∣x)p(x)p(x|y_1)\propto p(y_1|x)p(x) p(x∣y1)∝p(y1∣x)p(x)
p(x∣y1,y2)∝p(y1,y2∣x)p(x)=p(y2∣x)p(y1∣x)p(x)∝p(y2∣x)p(x∣y1)\begin{aligned}p(x|y_1, y_2) &\propto p(y_1, y_2 | x)p(x) \\ &= p(y_2 | x)p(y_1|x)p(x) \\ &\propto p(y_2|x)p(x|y_1)\end{aligned} p(x∣y1,y2)∝p(y1,y2∣x)p(x)=p(y2∣x)p(y1∣x)p(x)∝p(y2∣x)p(x∣y1)
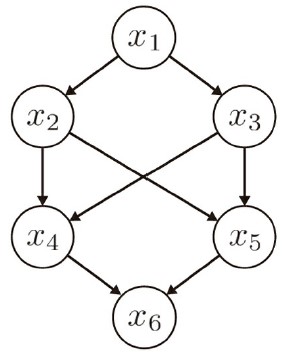
p(x1,x2,x3,x4,x5,x6)=p(x2∣x1)p(x3∣x1)p(x4∣x2,x3)p(x5∣x2,x3)p(x6∣x4,x5)p(x_1,x_2,x_3,x_4,x_5,x_6) = p(x_2|x_1)p(x_3|x_1)p(x_4|x_2, x_3)p(x_5|x_2, x_3)p(x_6|x_4, x_5) p(x1,x2,x3,x4,x5,x6)=p(x2∣x1)p(x3∣x1)p(x4∣x2,x3)p(x5∣x2,x3)p(x6∣x4,x5)
式はp(x,y,z)=p(x)p(y∣x)p(z∣y)p(x,y,z) = p(x)p(y|x)p(z|y)p(x,y,z)=p(x)p(y∣x)p(z∣y) 事後分布は?
p(x,z∣y)=p(x,y,z)p(y)=p(x∣y)p(z∣y)\begin{aligned}p(x,z|y) &= \frac{p(x,y,z)}{p(y)} &= p(x|y)p(z|y)\end{aligned} p(x,z∣y)=p(y)p(x,y,z)=p(x∣y)p(z∣y)
もともと xxx と zzz の間にあった関係は yyy が与えられたことで消えて、xxx と zzz は独立になった
p(x,z∣y)=p(x,y,z)p(y)=p(x)p(y∣x,z)p(z)p(y)\begin{aligned}p(x,z|y) &= \frac{p(x,y,z)}{p(y)} &= \frac{p(x)p(y|x,z)p(z)}{p(y)} \end{aligned} p(x,z∣y)=p(y)p(x,y,z)=p(y)p(x)p(y∣x,z)p(z)
TODO:
p(X∣D)=p(D∣X)p(X)p(D)p(X|D) = \frac{p(D|X)p(X)}{p(D)} p(X∣D)=p(D)p(D∣X)p(X)
P(Y,X,w)=p(w)∏n=1Np(yn∣xn,w)p(xn)P(\bm{Y}, \bm{X}, \bm{w}) = p(\bm{w}) \prod_{n=1}^N p(y_n|\bm{x}_n, \bm{w})p(\bm{x}_n) P(Y,X,w)=p(w)n=1∏Np(yn∣xn,w)p(xn)
p(w∣Y,X)=p(Y,X∣w)p(w)p(Y,X)=p(Y∣X,w)p(X)p(w)p(Y∣X)p(X)∝p(w)∏n=1Np(yn∣xn,w)\begin{aligned} p(\bm{w}|\bm{Y}, \bm{X}) &=\frac{p(\bm{Y}, \bm{X}|\bm{w})p(\bm{w})}{p(\bm{Y}, \bm{X})} \\ &= \frac{p(\bm{Y} | \bm{X}, \bm{w})p(\bm{X})p(\bm{w})}{p(\bm{Y}|\bm{X}) p(\bm{X})} \\ &\propto p(\bm{w})\prod_{n=1}^Np(y_n|\bm{x}_n, \bm{w}) \end{aligned} p(w∣Y,X)=p(Y,X)p(Y,X∣w)p(w)=p(Y∣X)p(X)p(Y∣X,w)p(X)p(w)∝p(w)n=1∏Np(yn∣xn,w)
p(y∗∣x∗,Y,X)=∫p(y∗∣x∗,w)p(w∣Y,X)dwp(y_* | x_*, \bm{Y}, \bm{X}) = \int {p(y_*|x_*, \bm{w})p(\bm{w}|\bm{Y}, \bm{X}) dw} p(y∗∣x∗,Y,X)=∫p(y∗∣x∗,w)p(w∣Y,X)dw
相談:
TODO: 余裕があればパラメータ推定の話をここに入れる